




When hearing about Digital Preservation (DP) for the first time, thoughts often go to long-term storage – but DP is much more and concerns many different areas and processes. These processes can often be automated, but qualified people working in DP, dealing with the devil in the details, are absolutely necessary.
by Katharina Markus
Various challenges when preserving objects over the long-term
DP’s aim is preserving reusability of digital objects and their information over the long-term. When envisioning problems regarding reusability in e. g. 50 years, various aspects come to mind: structural (e. g. no funding), technical (e. g. no usable file format) and content-related (e. g. outdated content description). DP generally tries to deal with all of these. Various preservation actions have been established: for storage e. g. checksum checks, for content reusability complete and up-to-date metadata. But what about the area in between storage and content – preserving the display of file content (also “rendering”) in viewers and its execution? In that context, the DP community relies mainly on (format-) migration and emulation.

Set-up of digital preservation at ZB MED
Migration is also the primary preservation action for the department Digital Preservation (Digitale Langzeitarchivierung, dLZA) at ZB MED. It uses Rosetta from ExLibris as its digital preservation system, which not only supports migration but also checks files upon transfer into the system (among other things). If Rosetta, for example, finds a corrupted file, the department has to decide on how to proceed. Although various well-established standards and models exist within the DP-community (OAIS [1], PREMIS [2], Levels of Digital Preservation [3], dpc RAM [4], Thibodeau Object Levels of Preservation [5]), which are also integrated into und correspond with Rosetta’s set-up, the day-to-day details often require individual decisions.
Scenarios regarding long-term preservation
In the following, four scenarios introduce challenges and possible approaches in digital preservation. These are based on experiences of the DP-department at ZB MED, on experiences of departments at other institutions and on extrapolated future scenarios.
Scenario 1: Obsolete file format
A format is about to become obsolete and a solution is needed for all files using this format. The DP-team has to check whether its DP-system contains files with this format, select those and, if possible, migrate them to a new format. The DP-community developed a format registry [6], which contains format signatures as well as format identifiers. Tools [7] using that format registry can match a specific format identifier to files by recognizing their format signature. The format identifier can be documented in metadata [8] and, accordingly, the files can be selected in the system by searching for that identifier. The migration of the selected files depends, again, on finding a fitting tool. Many tools are documented in a tool registry by the community [9] or the search for a possible solution is forwarded into the community. Problems arise not only due to obsolete formats but also due to old format versions. The format registry PRONOM differentiates between these as well and provides specific identifiers [10]. Accordingly, the DP-team can select files with old format versions for migration.
An important part of migration is reviewing the migration result. If files change due to migration, the DP-team has to decide whether these changes are acceptable. The team usually uses a test data set and documents the decision in the DP-system. If the data provider still exists, DP-team and data provider can come to a joint decision. Metadata extracted from files before and after migration may help with automated quality control. A script can detect unwanted effects in single files within large data sets, for example a change in video length.
Scenario 2: Defective file between many intact files
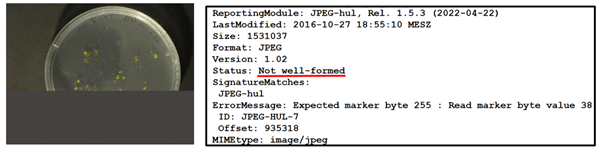
Single files in large data sets may contain defects, but the DP-team cannot open and check every file. Still, it wants to find these files and repair or replace them. The DP-community uses format validation tools [11] for that purpose, which check whether the file conforms to the relevant file format standard. Automated processes using these tools can identify all files which aren’t “well-formed” and “valid”. The DP-team then analyses the problematic files and opens them in various viewers. The detected problems can have effects ranging from “file content cannot be displayed” to “display as intended”. The DP-team in general tries to understand the error message [12] and aims to repair the file. Migration to a similar file format is in some cases sufficient to solve the problem, in others a tool from the aforementioned tool registry [9] may be necessary. A set of files sometimes can also be made well-formed and/or valid by writing a script oneself, altering a detail in the files. For files stored within a DP-system, repair procedures are documented in the system and the file is versioned. If the data provider is still available the DP-team can also ask for a replacement file.
If reasons for the invalidity remain unclear, the DP-team has to decide whether they declare any possible effects as uncritical for future reuse, as unclear or as critical. Sometimes further investigation is necessary.
Scenario 3: Obsolete file components

In case some files are using an old or unusual color space [13] which isn’t compatible with recent popular viewers, the contents of the files may be displayed incorrectly. The DP-team now has to select the files using the problematic color space within their DP-system. In many image files such information is embedded into the file itself, as file-specific metadata. If respective tools are available and formats aren’t proprietary, tools can extract that metadata. In some DP-systems, like Rosetta, extraction of technical (file-specific) metadata is part of the regular processes, using format-specific plug-ins. The extracted technical metadata is also indexed in the system, allowing the search for files with metadata entries containing the problematic color space. Altering the files, resulting in a correct color display depends again on repair- and migration-tools (see also scenario 1 and 2). Often the DP-team is dependent on the larger community, has to test possible solutions and, once it finds an interesting tool, may still need to program an automated workflow itself.
Scenario 4: Incomplete data delivery

A DP-department receives large data sets consisting of a regular structure from a data provider. The amount of data makes completeness checks by humans impossible. The DP-department wants to check automatically for completeness, using information inherent in the data. Such a check for example is possible for journals, using volume and issue numbers in xml files of articles. The department has to write its own script which recognizes gaps in these numbers [14].
This last scenario differs a bit from the other more technical ones before. Still, it shows the importance of deliberate quality control (e. g. completeness checks) and the willingness generating a technical basis for that.
These scenarios are just selections of possible scenarios, neglecting e. g. rights issues or preservation of software or websites. For complex objects emulation might be a better solution instead of migration when preserving their reusability, which comes with its own challenges. Information on old storage devices, like e. g. CD-ROMs or floppy disks again depend on separate processes and solutions. And knowing about endangered formats early enough is yet another challenge.
Still, many solutions and standards have been developed within the DP-community. And the file-specific tools, registries and standards mentioned in this blog post are achievements of the DP-community and were already able to uncover interesting problem cases.
Acknowledgement:
Many thanks to Yvonne Tunnat (ZBW) for feedback on the article.
DOI (Digitalausgabe): https://doi.org/10.48664/yvwc-0v55
Quellen
[1] OAIS: Open Archival Information System: Consultative Committee for Space Data Systems: CCSDS (2012) CCSDS 650.0-M-2. Reference model for an open archival information system (OAIS). https://public.ccsds.org/Pubs/650x0m2.pdf (last accessed 13.10.2022). ISO 14721:2012 Space data and information transfer systems — Open archival information system (OAIS) — Reference model. https://www.iso.org/standard/57284.html (last accessed 13.10.2022).
[2] PREMIS: Preservation Metadata Implementation Strategy https://www.loc.gov/standards/premis/ (last accessed 13.10.2022)
[3] Levels of Digital Preservation https://ndsa.org/publications/levels-of-digital-preservation/ (last accessed 13.10.2022)
[4] dpc RAM: Digital Preservation Coalition Rapid Assessment Model https://www.dpconline.org/digipres/dpc-ram (last accessed 13.10.2022)
[5] Thibodeau Object Levels of Preservation: Lindlar et al. (2020) “You say potato, I say potato” Mapping Digital Preservation and Research Data Management Concepts towards Collective Curation and Preservation Strategies, International Journal of Digital Curation, 5, 1. p. 6-9. https://doi.org/10.2218/ijdc.v15i1.728 (last accessed 13.10.2022). Thibodeau (2002) Overview of technological approaches to digital preservation and challenges in coming years. P. 4-31. In “The state of digital preservation: an international perspective, ISNB 1-887334-92-0.
[6] PRONOM Format Registry: PRONOM is hosted and maintained by the National Archives. It is openly accessible and format signatures are developed by the DP-community. https://www.nationalarchives.gov.uk/PRONOM/Default.aspx (last accessed 13.10.2022). Format signatures are bit patterns characteristic for the format.
[7] Format identification tools like DROID (from the National Archives) and Siegfried (Richard Lehane) use format signatures from the PRONOM format registry. Specifically Siegfried uses format signatures from PRONOM, MIME-info file format signatures, Library of Congress FDD file format signatures and wikidata (the last one in beta). (https://github.com/richardlehane/siegfried (last accessed 13.10.2022)). DROID uses just PRONOM-format signatures (https://www.nationalarchives.gov.uk/information-management/manage-information/preserving-digital-records/droid/ (last accessed 13.10.2022)).
[8] Matching information to files: this is achieved by documenting the information in PREMIS-metadata, which are partly files-specific. Accordingly, file-specific information like checksums, format identifier and results of quality control like validity checks can be documented automatically.
[9] Tool Registry COPTR https://coptr.digipres.org/index.php/Main_Page (last accessed 13.10.2022)
[10] A search in PRONOM with the file extension “PDF” results in 39 different PDF-versions (10.10.2022).
[11] Format validators like JHOVE (OPF) and veraPDF (veraPDF consortium) are well known in the DP-community. JHOVE can validate various formats (https://openpreservation.org/tools/jhove/, last accessed 13.10.2022), while veraPDF is specific for PDF/A (https://verapdf.org/, last accessed 13.10.2022). A selection of further validators: Jpylyzer fpr jp2-files (OPF, https://openpreservation.org/tools/jpylyzer/, last accessed 13.10.2022), Exiftool for PDF (Phil Harvey, https://exiftool.org/, last accessed 13.10.2022).
[12] Examples for PDF-error messages and possible approaches: Yvonne Tunnat (2020) Convert me if you can – Preservation Planning with malicious PDFs https://openpreservation.org/blogs/convert-me-if-you-can-preservation-planning-with-malicious-pdfs/?q=115 (last accessed 13.10.2022). Yvonne Tunnat (2022) PDF Validation with ExifTool – quick and not so dirty https://openpreservation.org/blogs/pdf-validation-with-exiftool-quick-and-not-so-dirty/?q=1 (last accessed 13.10.2022).
[13] An example for an assessment of a color space of TIFF-files as non-conformant to the specifications of an institution. Franziska Geisser (2017) Handling File Format Issues in Rosetta – and Beyond https://www.youtube.com/watch?v=nyNaNJDebI4&ab_channel=ExLibrisLtd (last accessed 13.10.2022). [14] An example for establishing automated completeness checks for journal articles: Micky Lindlar (2021) What are we missing? Completeness checking with e-journals and why we should care. https://www.dpconline.org/blog/wdpd/mlindlar-wdpd21 (last accessed 13.10.2022).